В статье описаны принципы работы, пошаговая инструкция и API модуля для создания собственного адаптера ИИ-ассистента. Как настроить работу с ИИ-ассистентом в интерфейсе платформы см. в статье Работа с ИИ-ассистентом.
Что такое адаптер
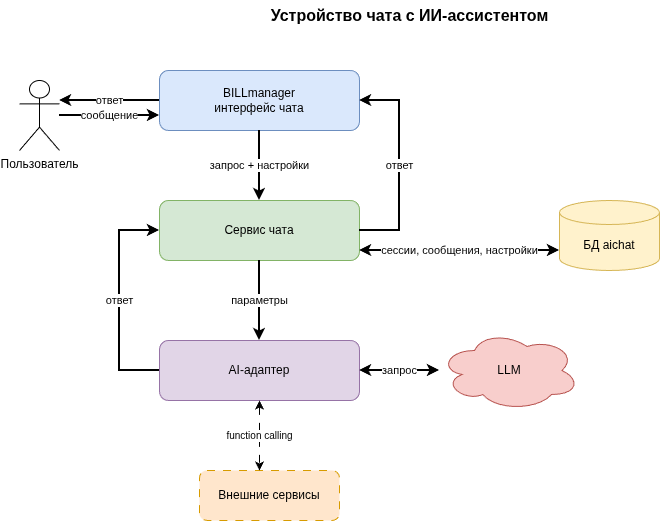
Адаптер — модуль, который связывает чат с внешним LLM-провайдером (OpenAI-совместимый API, Yandex GPT, собственный сервис и т.п.). Сервер чата не обращается к провайдеру напрямую: он передаёт запрос зарегистрированному адаптеру, а адаптер возвращает ответ в едином внутреннем формате.
Возможности механизма адаптеров:
- подключение произвольного LLM без изменения кода сервера;
- использование нескольких адаптеров в одном экземпляре чата. Например, для разных провайдеров можно использовать различные адаптеры;
- поддержка потоковой (SSE) и стандартной генерации ответа;
- управление моделями: адаптер может опционально передавать список поддерживаемых моделей для выбора в настройках BILLmanager;
- реализация собственной логики работы с LLM. Например, вызов функций (function calling), фильтрация запросов и т.д;
- передача API-ключа, URL-адреса и системного промпта из настроек проекта.
Собственные адаптеры загружаются автоматически при старте сервера чата из каталога /app/server/adapters / внутри Docker-контейнера. Пересборка образа не требуется — достаточно разместить файл адаптера в контейнере и перезапустить контейнер.
Встроенные адаптеры
После установки модуля "ИИ-ассистент" в платформе доступны следующие адаптеры:
Создание адаптера
Ниже приведена инструкция по созданию адаптера для общения с LLM через пакет OpenAI. В примере использовано название адаптера my-llm. Вместо my-llm вы можете указать другое имя.
Чтобы создать адаптер для общения с LLM через пакет OpenAI:
- Создайте файл адаптера [имя-адаптера].adapter.js. Например, my-llm.adapter.js.
- Создайте класс адаптера и реализуйте необходимые методы:
getName— получение имени адаптера;getCompletion— получение ответа от ИИ без SSE;getCompletionStream— получение ответа от ИИ с SSE.
Пример создания адаптера -
Скопируйте файл адаптера в каталог /app/server/adapters работающего контейнера чата. Чтобы сохранить добавленные адаптеры после пересоздания образа, создайте свой образ на базе Docker-образа чата.
Где:Пример создания образа с помощью DockerfileFROM docker-registry.ispsystem.com/ispsystem5/chat:1.0.0 WORKDIR /app COPY ./my-llm.adapter.js ./server/adapters/my-llm.adapter.jsdocker-registry.ispsystem.com/ispsystem5/chat:1.0.0— адрес к публичному образу контейнера чата.
- Создайте образ из Dockerfile:
docker build . -t my-llm - Укажите тег созданного образа в скрипте для управления образами чата /usr/local/mgr5/etc/docker/services/aichat.sh. Замените переменную
SERVICE_IMAGEна тег нового образаSERVICE_IMAGE="my-llm" - Перезапустите контейнер чата:
sh etc/docker/services/aichat.sh restart - В веб-интерфейсе BILLmanager перейдите в раздел ИИ-ассистент → Настройки → выберите ИИ-ассистента → кнопка Изменить.
- В блоке Основное в поле Адаптер выберите новый адаптер.
- Задайте необходимые настройки: API URL, API-ключ. Подробнее см. статью Работа с ИИ-ассистентом.
- Сохраните изменения.
После настройки чат готов к использованию. Запросы будут отправляться через созданный адаптер.
Написание адаптера с внешними зависимостями
Сервис чата импортирует файлы, оканчивающиеся на .adapter.js . Если в этом файле нужно использовать зависимости (например, директорию node_modules) или пакеты, их нужно также перенести внутрь контейнера в директорию /app/server/adapters/.
При перемещении каталога node_modules внутрь контейнера зависимости становятся доступны через импорт require.
// Библиотека OpenAI доступна для импорта по умолчанию.
const OpenAI = require('openai');
// Пример импорта зависимости при переносе node_modules с необходимыми зависимостями в директорию /app/server/adapters/
const customPackage = require('custom-package');
class MyLLMAdapter {
...
}
module.exports = { MyLLMAdapter };API адаптера
Описание функций
getName()
Возвращает уникальное строковое имя адаптера.
getCompletion(params)
Синхронная генерация ответа без потока.
getCompletionStream(params)
Потоковая генерация ответа для режима SSE.
getModels()
Возвращает список моделей, доступных для выбора в настройках.
Описание интерфейсов
ModelStreamEvent
Событие потока (для SSE) — один из следующих типов:
text_delta — промежуточный фрагмент текста.
completed — завершение генерации (обязательное финальное событие).
tool_call — уведомление о вызове инструмента.