
Меня зовут Александр Гришин, и я работаю продакт-менеджером платформы виртуализации VMmanager. Недавно мы выпустили автономные Unbreakable кластеры, с их помощью можно организовать инфраструктуру высокой доступности и обеспечить непрерывность бизнес-процессов компании. Если один из физических серверов в отказоустойчивом кластере выйдет из строя, виртуальные машины восстановятся на исправном узле, автоматически и с минимальным простоем.
При реализации мы учитывали опыт предыдущей версии нашего продукта — VMmanager Cloud — и изучили лучшие практики у конкурентов, таких как Proxmox, OpenStack, VMware и другие. Узнать, как работает сервис, можно из видео ниже. А подробнее об устройстве сервиса «под капотом» я расскажу в этой статье.
Cодержание
Словарик
Узел — физический сервер с установленной на него операционной системой (CentOS 7/8, РедОС 7.2/7.3 или AlmaLinux 8). Узел выполняет роль гипервизора и служит «точкой выполнения» для виртуальных машин.
Кластер — группа узлов, находящихся в одной локации. В рамках кластера могут определяться:
- политики распределения виртуальных машин;
- настройка high availability;
- сетевая абстракция для SDN (IP-fabriс или VxLAN).
HA (high availability) — подход к ИТ-системе, когда риск аварийных ситуаций и ущерб от них сводится к минимуму, а сервисы работают максимально непрерывно.
Unbreakable кластер — так мы называем кластер высокой доступности в VMmanager.
Детали реализации алгоритма
Для реализации автономных unbreakable кластера команде VMmanager необходимо было решить классическую задачу достижения консенсуса в распределённых системах. Так мы адаптировали алгоритм из семейства Paxos под специфику продукта.
Идея алгоритма в том, что один из узлов такого кластера берёт на себя роль лидера и получает возможность принимать решения на уровне всего кластера. Алгоритм гарантирует, что в любой момент времени в кластере может быть только один лидер.
В нашем варианте реализации алгоритма используется два основных фактора определения доступности узла:
- доступность на уровне управляющей сети;
- доступность на уровне сетевого хранилища.
Дополнительный фактор определения — проверочный IP-адрес. Он позволяет выявить ситуацию, когда узел потерял доступ к управляющей сети, но сеть для виртуальных машин всё ещё доступна.
Для определения доступности на уровне сети и обмена сообщениями между узлами применяется связка Сorosync + kronosnet. Использование модели обмена сообщениями Сorosync гарантирует, что все узлы получают отправленные сообщения в одном и том же порядке.
Проверки на уровне сетевого хранилища используются для определения второго фактора доступности узла. Узлы могут сохранять в сетевом хранилище свои метаданные, и следить за метаданными кластера. Этими данными может управлять только действующий лидер. По этому, для активации отказоустойчивости при использовании CEPH, необходимо, чтобы в хранилище была настроена файловая система . При использовании SAN хранилища дополнительных настроек не потребуется.
При подготовке узла к подключению в отказоустойчивый кластер платформа самостоятельно устанавливает и настраивает демон для синхронизации системных часов.
За сбор, анализ, обмен информацией и принятие решения на стороне узла отвечает служба HA agent, она является частью VMmanager.
Со стороны мастера платформы эти процедуры осуществляет микросервис HA-watch. Он отвечает за общение платформы с HA agent'ом узла. HA agen, который является на данный момент мастером, имеет право на принятие решения о процедурах восстановления в случае аварии.
Активация отказоустойчивости в кластере
Важный этап активации отказоустойчивости в кластере — это выборы лидера. Выборы лидера инициируются в следующих ситуациях:
- при включении отказоустойчивости на кластере из интерфейса;
- при выходе действующего лидера из строя;
- при изменении конфигурации отказоустойчивости в кластере;
- при обновлении версии компонентов отвечающих за отказоустойчивость в кластере.
Для успешных выборов необходимо, чтобы узлов-выборщиков было не менее N/2 + 1, где N — общее количество узлов в кластере. Например, в кластере из двух узлов оба должны быть активны, а в кластере из 17 узлов будет достаточно 9. Алгоритм гарантирует, что информация о порядке готовности узлов одинакова для всех участников кластера.
При выборе лидера каждый из узлов-выборщиков рассчитывает свой приоритет с помощью алгоритма, реализованного в ha-agent, и сообщает его остальным участникам кластера. Узел с самым большим приоритетом выбирается лидером. Когда все приоритеты будут известны, и все узлы-выборщики подтвердят что определили лидера, кластер начнёт работу в режиме отказоустойчивости.
Узлы которые были не готовы к началу выборов ждут завершения выборов и затем присоединяются к кластеру. При добавлении новых узлов в отказоустойчивый кластер они подчиняются уже существующему лидеру.
Если исправных узлов в кластере меньше, чем необходимо, процедура выборов не начнется.
Статусы узлов в кластере
Для узлов в кластере существует несколько статусов. Они отражают роль или состояние сервера в данный момент, это два «хороших» статуса:
- Лидер. Узел является лидером в своем кластере.
- Участник. Узел является простым участником кластера.
И три статуса отражающих аварийную ситуацию:
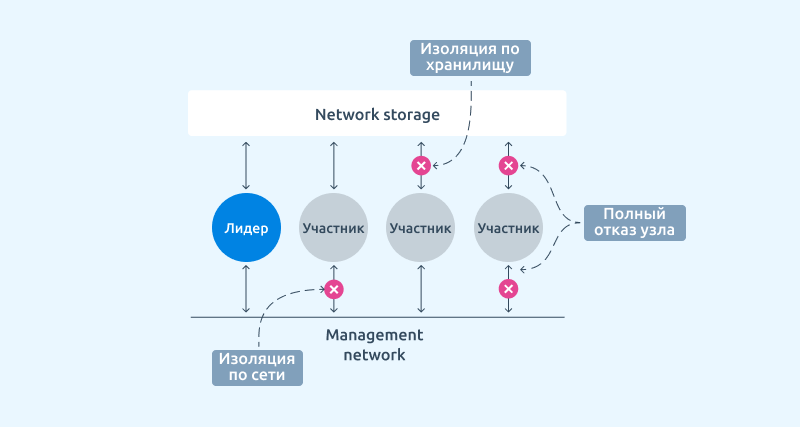
- Изоляция по сети — статус сообщающий о аварийной ситуации связанной с сетью.
- Изоляция по хранилищу — статус сообщающий о аварийной ситуации связанной с доступом к СХД
- Полный отказ. Статус отражающий что узел совершенно не доступен.
Во всех аварийных ситуациях платформа начинает процедуры восстановления виртуальной инфраструктуры.
Есть еще два дополнительных статуса для узлов:
- Выход из unbreakable кластера. Узел переходит в него, когда становится недоступным по сети. Однако эта ситуация отличается от статуса изоляция по сети тем, что проверочный IP-адрес остается доступным для узла (его можно указать в настройках кластера). В таком случае платформа не начинает процедуру релокации виртуальной машины.
- Сеть нестабильна. Статус определяется, если сеть недоступна менее 15 секунд и это повторяется регулярно. Узел то доступен, то снова недоступен по сети. Восстановительных действий предприниматься не будет, но в платформе для этого узла будет отображён этот статус.
Эти статусы не являются триггерами к началу процедуры восстановления, но информируют администратора о проблеме с узлами.
Аварийное восстановление в кластере
Когда узел определяет у себя один из статусов он останавливает все виртуальные машины и пытается сообщить о своем статусе лидеру кластера, однако лидер способен и сам определить что какой-то из узлов перешел в аварийный статус. После этого начинается процедура восстановления виртуальных машин согласно настроенным приоритетам.
В отказоустойчивом кластере действуют особые правила для запуска виртуальных машин после перезагрузки узла. Виртуальная машина запускается только при соблюдении двух условий:
- у узла должен быть хороший статус;
- виртуальная машина должна одновременно принадлежать только одному узлу.
Информацию о статусе узла платформа сохраняет в метаданных кластера. Такой подход позволяет избежать сценария Split Brain, когда к одному диску подключаются одновременно две виртуальные машины.
Если узел переходит в плохой статус, но не может самостоятельно перезапустить виртуальные машины, он перезагружается с системным вызовом от HA-agent либо демона .
При отказе узла восстанавливаются только виртуальные машины с активированным параметром «Отказоустойчивость». Поэтому администратор должен заранее активировать этот параметр у виртуальных машин.
Тайминги — важная характеристика для оценки бесперебойности бизнес-процессов, потому что от них зависит уровень SLA. На данный момент мы имеем следующие значения:
- Время выбора лидера — не более 15 секунд при условии, что узлов-выборщиков достаточно.
- Время распознавания плохого статуса — от 15 секунд, но не больше 1 минуты (в зависимости от аварийной ситуации).
- Время релокации — несколько секунд, так как диски виртуальных машин находятся в сетевом хранилище.
- Длительность простоя виртуальной машины складывается из времени на распознавание плохого статуса и времени на релокацию и запуск ВМ на новом узле.
Для активации отказоустойчивости кластер должен состоять как минимум из двух узлов, использовать сетевое хранилище (CEPH или SAN), и использовать KVM виртуализацию. Подробнее о требованиях к кластеру в нашей документации.
Отказоустойчивость платформы
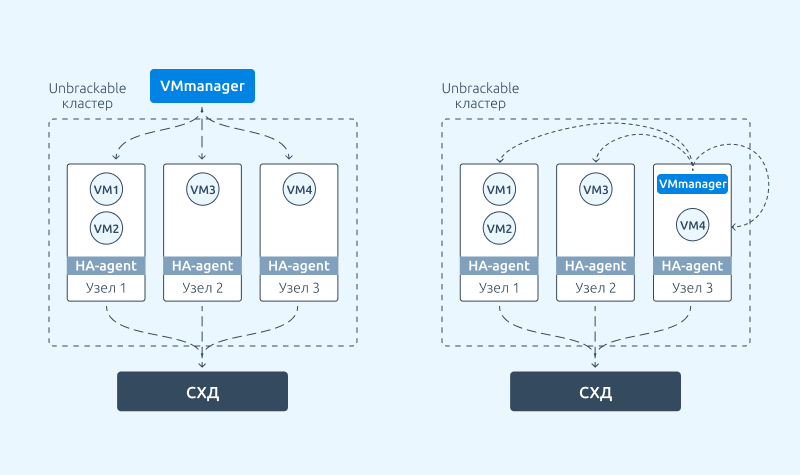
VMmanager спроектирован таким образом, что процедуры восстановления в каждом кластере обеспечиваются за счет HA-агентов и не зависят от мастера платформы. Это значит, что выход из строя сервера с VMmanager никак не повлияет на обеспечение отказоустойчивости внутри кластеров.
Однако с помощью unbreakable кластера можно обеспечить устойчивость самой платформы VMmanager. Для этого поддерживается конфигурация, при которой мастер платформы переносится на одну из отказоустойчивых виртуальных машин внутри платформы. Так, в случае аварии на сервере с мастером платформы, автономный Unbreakable кластер восстановит работоспособность виртуальной машины с VMmanager.
Сейчас настроить эту конфигурацию можно вручную. В будущем такая возможность появится в настройках платформы, и это можно будет сделать в несколько кликов через интерфейс.
Про импортозамещение
VMmanager с автономными Unbreakable кластерами подходит для импортозамещения серверной виртуализации. Он находится в . А Unbreakable кластеры поддерживают использование операционных систем РедОС 7.2 и РедОС 7.3 на узлах. В будущем мы рассмотрим возможность поддержки этой функциональности в ОС Аstra Linux на узлах с процессорами Байкал-S.
Еще немного о планах
Мы продолжим развивать функциональность отказоустойчивости в VMmanager в единой экосистеме продуктов ISPsystem. Так, планируем реализовать концепцию proactive high availability. Она будет реализована в связке с другим нашим продуктом — платформой для управления оборудованием DCImanager. Proactive high availability будет анализировать состояние узлов на уровне оборудования в ДЦ и поможет предсказывать его выход из строя, а затем релоцировать важные виртуальные машины на «здоровые» узлы заранее.


