
Как изменить архитектуру монолитного продукта, чтобы ускорить его развитие, и как поделить одну команду на несколько, сохранив согласованность работы? Для нас ответом на эти вопросы стало создание нового API. Ниже обстоятельная история о пути к такому решению и обзор выбранных технологий, но для начала — небольшое лирическое отступление.
Несколько лет назад я прочёл в научной статье, что для полноценного обучения нужно всё больше и больше времени, а в недалёком будущем на получение знаний будет уходить восемьдесят лет жизни. Видимо, в IT это будущее уже наступило.
Мне посчастливилось начать программировать в те годы, когда не было разделения на бэкенд и фронтенд-программистов, когда не звучали слова «прототип», «продуктолог», «UX» и «QA». Мир был проще, деревья выше и зеленее, воздух чище и во дворах играли дети, а не парковались автомобили. Как бы мне ни хотелось вернуться в то время, нужно признать, что всё это не замысел суперзлодея, а эволюционное развитие общества. Да, общество могло развиваться иначе, но, как известно, история не терпит сослагательного наклонения.
Предыстория
BILLmanager появился как раз в те времена, когда не было жёсткого разделения по направлениям. Он имел согласованную архитектуру, умел управлять поведением пользователя и его даже можно было расширять плагинами. Шло время, команда развивала продукт, и вроде всё было хорошо, но стали наблюдаться странные явления. К примеру, когда программист занимался бизнес-логикой, он начинал плохо верстать формы, делал их неудобными и сложными для восприятия. Или добавление, казалось бы, простой функциональности отнимало несколько недель: архитектурно модули были жёстко связаны, поэтому при изменении одного приходилось корректировать другой.
Про удобство, эргономику и глобальное развитие продукта вообще можно было забыть, когда приложение падало с неизвестной ошибкой. Если раньше программист успевал делать работу в разных направлениях, то с ростом продукта и требований к нему это стало невозможно. Разработчик видел картину в целом и понимал, что если функция не будет правильно и стабильно работать, то формочки, кнопочки, тесты и продвижение не помогут. Поэтому откладывал всё и садился за исправление злосчастной ошибки. Совершал свой маленький подвиг, который оставался никем не оценённым (сил на правильную подачу клиенту уже просто не было), но функция начинала работать. Собственно, чтобы эти маленькие подвиги доходили до клиентов, в команде и появились люди, ответственные за разные направления: фронтенд и бэкенд, тестирование, дизайн, поддержку, продвижение.
Но это было только первым шагом. Команда изменилась, а архитектура продукта осталась технически сильно связанной. Из-за этого не получалось развивать приложение требуемыми темпами, при изменении интерфейса приходилось менять логику бэкенда, хотя структура самих данных часто оставалась неизменной. Со всем этим надо было что-то делать.
Фронтенд и бэкенд
Стать профессионалом во всём — долго и дорого, поэтому современный мир прикладных программистов делится, в основной своей массе, на фронтенд и бэкенд.
Здесь вроде всё понятно: набираем фронтенд-программистов, они будут отвечать за пользовательский интерфейс, а бэкенд наконец-то сможет сфокусироваться на бизнес-логике, моделях данных и других подкапотных вещах. При этом бэкенд, фронтенд, тестировщики и дизайнеры останутся в одной команде (ведь они делают общий продукт, просто фокусируются на разных его частях). Быть в одной команде — значит иметь одно информационное и, желательно, территориальное пространство; вместе обсуждать новые фичи и разбирать законченные; согласовывать работу над большой задачей.
Для какого-то абстрактного нового проекта этого будет достаточно, но у нас уже было написанное приложение, а объёмы планируемых работ и сроки их реализации явно указывали, что одной командой обойтись не получится. В баскетбольной команде пять человек, в футбольной — 11, а у нас было около 30. Под идеальную скрам-команду из пяти — девяти человек это никак не подходило. Надо было разделиться, но как при этом сохранить связность? Чтобы сдвинуться с места, нужно было решить архитектурную и организационную проблемы.

«Всё сделаем в одном проекте, так будет удобнее» — говорили они...
Архитектура
Когда продукт устарел, кажется логичным отказаться от него и писать новый. Это хорошее решение, если можно спрогнозировать время и оно всех устроит. Но в нашем случае даже при идеальных условиях разработка нового продукта заняла бы годы. Помимо этого, специфика приложения такова, что перейти со старого на новое при полном их различии было бы крайне сложно. Нашим клиентам очень важна обратная совместимость, и если её не будет, они откажутся переходить на новую версию. Целесообразность разработки с нуля в таком случае сомнительна. Поэтому мы решили модернизировать архитектуру существующего продукта с сохранением максимальной обратной совместимости.
Наше приложение — это монолит, интерфейс которого строился на стороне сервера. Фронтенд только реализовывал полученные от него инструкции. Иными словами, за интерфейс пользователя отвечал не фронтенд, а бэкенд. Архитектурно фронтенд и бэкенд работали как одно целое, поэтому изменяя одно, мы были вынуждены менять другое. И это не самое страшное, что гораздо хуже — нельзя было разрабатывать пользовательский интерфейс без глубокого знания происходящего на сервере.
Нужно было разделять фронтенд и бэкенд, делать отдельные программные приложения: только так можно было начать развивать их требуемыми темпами и объёмами. Но как делать два проекта параллельно, менять их структуру, если они сильно зависят друг от друга?
Решением стала дополнительная система — прослойка. Идея прослойки крайне проста: она должна согласовать работу бэкенда и фронтенда и взять на себя все дополнительные издержки. К примеру, чтобы при декомпозиции функции оплаты на стороне бэкенда прослойка комбинировала данные, а на стороне фронтенда ничего не нужно было менять; или чтобы для вывода на дашборд всех заказанных пользователем услуг мы не делали дополнительную функцию на бэкенде, а агрегировали данные в прослойке.
Помимо этого прослойка должна была добавить определённости в том, что можно позвать у сервера и что в итоге вернётся. Хотелось, чтобы запрос операций можно было делать без знания внутреннего устройства функций, которые их исполняют.

Повысили устойчивость, разделив зоны ответственности.
Коммуникации
Из-за сильной зависимости между фронтендом и бэкендом делать работу параллельно было невозможно, что тормозило обе части команды. Программно разделив один большой проект на несколько, мы получали свободу действий в каждом, но при этом нам нужно было сохранить согласованность в работе.
Кто-то скажет, что согласованность достигают с помощью повышения софт-скиллов. Да, их нужно развивать, но это не панацея. Посмотрите на дорожное движение, там тоже важно, чтобы водители были вежливы, умели объезжать случайные препятствия и помогали друг другу в сложных ситуациях. Но! Без правил дорожного движения мы даже при наилучших коммуникациях получили бы аварии на каждом перекрёстке и риск не доехать до места вовремя.
Нам нужны были правила, которые было бы сложно нарушить. Как говорится, чтобы их было проще соблюдать, чем нарушать. Но внедрение любых законов несёт не только плюсы, но и накладные расходы, а нам очень не хотелось тормозить основную работу, втягивая в процесс всех. Поэтому мы создали координационную группу, а потом и команду, целью которой стало создание условий для успешной разработки разных частей продукта. Она настроила интерфейсы, которые позволили разным проектам работать как одно целое — те самые правила, которые проще соблюдать, чем нарушать.
Мы называем эту команду «API», хотя техническая реализация нового API — это только малая часть её задач. Как общие участки кода выносят в отдельную функцию, так и команда API разбирает общие вопросы продуктовых команд. Именно здесь происходит соединение нашего фронтенда и бэкенда, поэтому участники этой команды должны понимать специфику каждого направления.
Возможно, «API» — не самое подходящее название для команды, больше подошло бы что-то про архитектуру или масштабное видение, но, думаю, это мелочь и сути не меняет.
API
Интерфейс доступа к функциям на сервере существовал и в нашем начальном приложении, но для потребителя выглядел хаотично. При разделении фронтенда и бэкенда нужно было больше определённости.
Цели для нового API сформировались из ежедневных трудностей в реализации новых продуктовых и дизайнерских идей. Нам были нужны:
- Слабая связанность компонентов системы, чтобы бэкенд и фронтенд можно было развивать параллельно.
- Высокая масштабируемость, чтобы новый API не мешал наращивать функциональность.
- Стабильность и согласованность.
Поиск решения для API начали не с бэкенда, как это обычно принято, а, наоборот — подумали, что нужно пользователям.
Наиболее распространены разного рода REST API. В последние годы к ним добавляют описательные модели через инструменты типа swagger, но нужно понимать, что это тот же REST. И, по сути, его главный плюс и в то же время минус — это правила, которые носят исключительно описательный характер. То есть никто не запрещает создателю такого API отклоняться от постулатов REST при реализации отдельных частей.
Другим распространённым решением является GraphQL. Он тоже не идеален, но в отличие от REST, GraphQL API — это не просто описательная модель, а настоящие правила.
Выше я говорил про систему, которая должна была согласовывать работу фронтенда и бэкенда. Прослойка (interlayer) — это именно тот промежуточный уровень. Рассмотрев возможные варианты работы с сервером, мы остановились на GraphQL в качестве API для фронтенда. Но, так как бэкенд написан на C++, то реализация GraphQL-сервера оказалась нетривиальной задачей. Не буду здесь описывать все возникшие сложности и ухищрения, на которые мы шли, чтобы их преодолеть, реального результата это не принесло. Посмотрели на проблему с другой стороны и решили, что простота — залог успеха. Поэтому остановились на проверенных решениях: отдельный Node.js сервер с Express.js и Apollo Server.
Далее нужно было решить, как обращаться к API бэкенда. Сначала смотрели в сторону поднятия REST API, потом пробовали использовать аддоны на C++ для Node.js. В итоге поняли, что это всё нам не подходит, и после подробного анализа для бэкенда выбрали API на базе gRPC-сервисов.
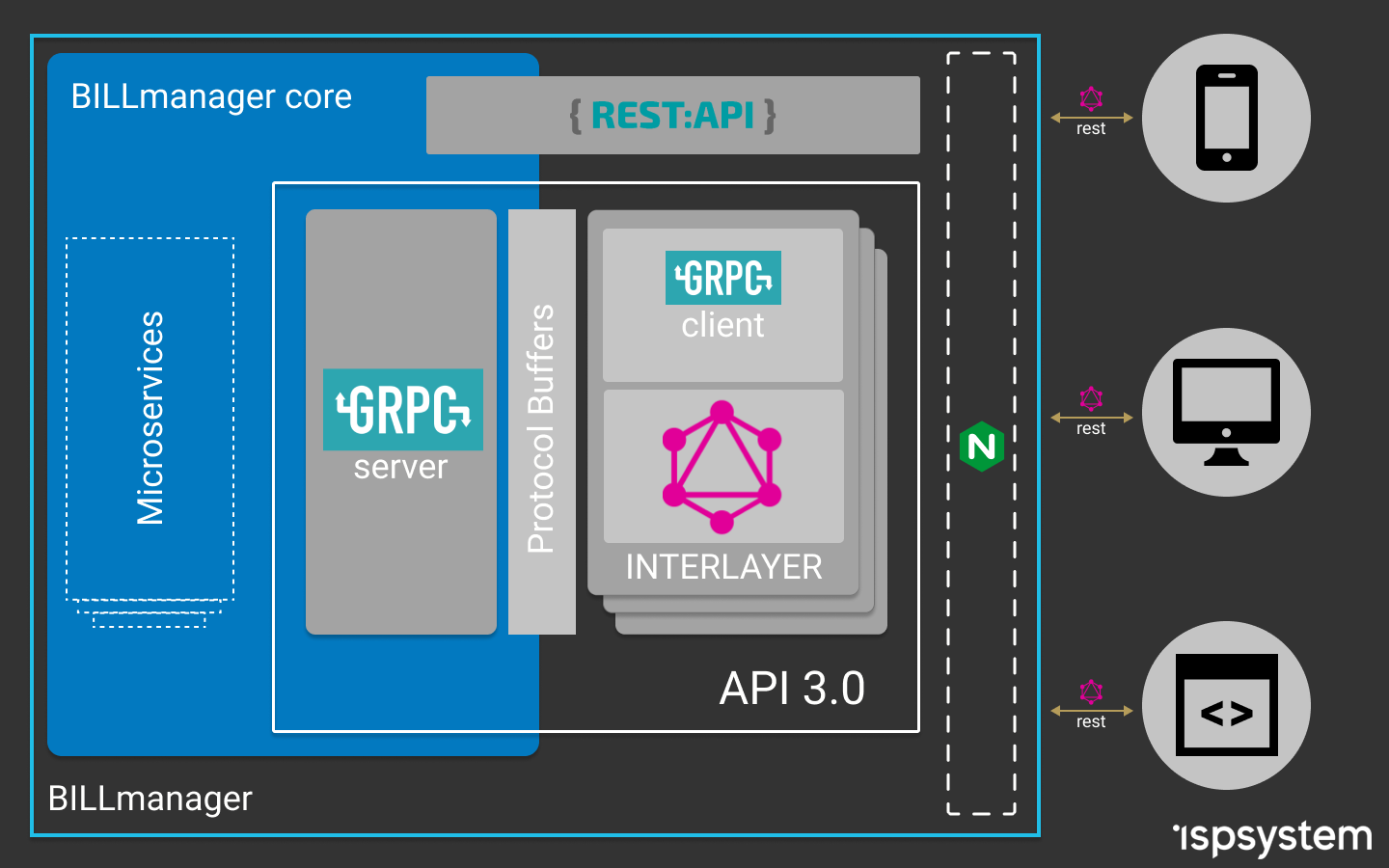
Собрав воедино полученный опыт использования C++, TypeScript, GraphQL и gRPC, мы получили архитектуру приложения, позволяющую гибко развивать бэкенд и фронтенд, продолжая при этом создавать единый программный продукт.
Получилась схема, где фронтенд общается с промежуточным сервером с помощью GraphQL-запросов (знает, что спросить и что получит в ответ). GraphQL-сервер в резолверах вызывает API функции gRPC-сервера, при этом для связи они используют Protobuf-схемы. API-сервер на базе gRPC знает, у какого микросервиса взять данные, или кому передать полученный запрос. Сами микросервисы при этом тоже построены на gRPC, что обеспечивает скорость обработки запросов, типизацию данных и возможность использования различных языков программирования для их разработки.
Общая схема работы после изменения архитектуры
Есть у этого подхода и ряд минусов, основным из них является дополнительная работа по настройке и согласованию схем, а также написанию вспомогательных функций. Но эти затраты окупятся, когда пользователей API станет больше.
Результат
Мы пошли эволюционным путём развития продукта и команды. Достигли успеха или затея обернулась провалом, наверное, судить рано, но можно подвести промежуточные итоги. Что имеем сейчас:
- За отображение отвечает фронтенд, а за данные — бэкенд.
- На фронтенде сохранилась гибкость в плане запросов и получения данных. Интерфейс знает, что можно попросить у сервера и какие ответы должны быть.
- На бэкенде появилась возможность менять код с уверенностью, что интерфейс у пользователя продолжит работать. Стал возможным переход на микросервисную архитектуру без необходимости переделывать весь фронтенд.
- Появилась возможность использования mock-данных для фронтенда, когда ещё не готов бэкенд.
- Создание схем совместной работы исключило проблемы взаимодействия, когда команды понимали одну и ту же задачу по-разному. Сократилось количество итераций по переделке форматов данных: действуем по принципу «семь раз отмерь, один раз отрежь».
- Появилась возможность планировать работы на спринт параллельно.
- Для реализации отдельных микросервисов теперь можно набирать разработчиков, не знакомых с C++.
Из всего этого главным достижением я бы назвал возможность осознанно развивать команду и проект. Думаю, нам удалось создать условия, в которых каждый участник может более целенаправленно повышать свои компетенции, фокусироваться на задачах и не распылять внимание. От каждого требуется работа только на своём участке, и теперь она возможна с высокой вовлечённостью и без постоянных переключений. Стать профессионалом во всём невозможно, но для нас это теперь и не нужно.
Статья получилась обзорной и очень общей. Её целью было показать путь и результаты сложной исследовательской работы на тему, как с технической точки зрения поменять архитектуру для продолжения развития продукта, а также продемонстрировать организационные сложности деления команды на согласованные части.
Здесь я поверхностно затронул вопросы командной и межкомандной работы над одним продуктом, выбор технологи API (REST vs GraphQL), связь Node.js приложения с C++ и т. д. Каждая из этих тем тянет на отдельную статью, и если вам будет интересно, то мы их обязательно напишем.
Добавьте реакцию


